アプリケーションの概要
ここで取り上げるアプリケーションは次のような要件を満たすように実装します。
住所録がExcelシートで存在しますが、残念なことに郵便番号が入力されていません。そのため記入されている住所を元に郵便番号を検索し、その結果を郵便番号欄に記録するというものです。
ここでは次の要素が登場します。
- ExcelシートをPythonプログラムで読み込む
- Pandasライブラリを使ってデータはDataFrameで操作する。
- 郵便番号検索をするために、HTTPsリクエストと結果のパースを行う
完成形のソースコード
hello_excel.py
#!/usr/bin/env python3.8
import re
import time
from html.parser import HTMLParser
import pandas as pd
import requests
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
class Parser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.parent = False
self.result = False
self.data = []
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
if tag == "dl" and "class" in attrs and attrs['class'] == "result mb10 cx":
self.parent = True
if self.parent is True and tag == "dt":
self.result = True
def handle_data(self, data):
if self.parent is True and self.result is True:
m = re.search("^\d{3}-\d{4}$", data)
# if m and m.start() == 3:
if m:
self.data.append(data)
self.title = False
self.link = False
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
df['郵便番号'] = ""
for index, row in df.iterrows():
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
if b:
address = row[2][:b.start()]
# print(address)
r = requests.get("https://postcode.goo.ne.jp/search/q/" + address + "/?type=address")
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
# print(r.text)
parser = Parser()
parser.feed(r.text)
parser.close()
if len(parser.data) == 0:
print()
for data in parser.data:
print(data)
df.at[index, '郵便番号'] = ','.join(parser.data)
else:
print("not matched!")
time.sleep(3)
df.to_excel('NEW_' + FILE_NAME, sheet_name='NEW_' + SHEET_NAME, index=False)
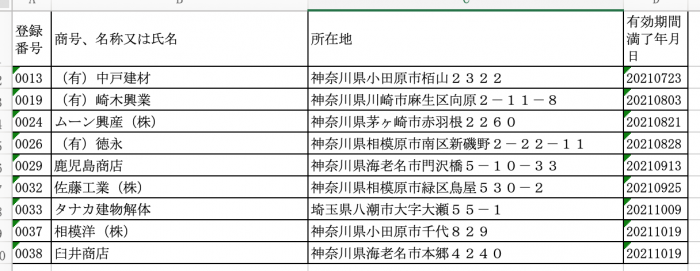
sample.xlsxの番号順シート
実装
ステップ0
以下の通り環境をセットアップします。
cd ${LearningPython_DIR}/src
mkdir HelloExcel
cd HelloExcel
pipenv install pandas
pipenv install xlrd
pipenv install openpyxl
pipenv install requests
ステップ1
#!/usr/bin/env python3.8 import pandas as pd FILE_NAME = "sample.xlsx" SHEET_NAME = "番号順" df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0) print(df)
解説
import pandas as pd
まずPandasを利用するのでこれをimportします。Pandasって何?って方もいらっしゃるかと思いますが、データ解析を支援する機能を提供するド定番のライブラリです。Pythonでデータ処理が必要となるとすぐに候補に挙がりますし実際よく使います。少しはこの具体的すぎる題材の価値が上がりましたでしょうか。
FILE_NAME = "sample.xlsx" SHEET_NAME = "番号順"
プログラムの前提として読み込むExcelファイルの名前は「sample.xlsx」です。
それから参照するシートの名前は「番号順」です。シートは番号でも指し示すことが出来ますが、そういったことは適宜ライブラリの仕様を確認して試してみてください。
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
Excelファイルを読み込んでいます。ファイル名、シート名、それからシート上の1行目がヘッダ行になっているのでそれを指定しています。読み込んだ値はDataFrameというオブジェクトになって格納されています。
このDataFrameというのが重要な鍵を握りますので、是非ともマスターしたいところです。この記事ではそのほんの一部ですがご紹介します。
print(df)
最後にDataFrameをprintしています。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample01.py
登録番号 商号、名称又は氏名 所在地 有効期間満了年月日
0 13 (有)中戸建材 神奈川県小田原市栢山2322 20210723
1 19 (有)崎木興業 神奈川県川崎市麻生区向原2-11-8 20210803
2 24 ムーン興産(株) 神奈川県茅ヶ崎市赤羽根2260 20210821
3 26 (有)徳永 神奈川県相模原市南区新磯野2-22-11 20210828
4 29 鹿児島商店 神奈川県海老名市門沢橋5-10-33 20210913
5 32 佐藤工業(株) 神奈川県相模原市緑区鳥屋530-2 20210925
6 33 タナカ建物解体 埼玉県八潮市大字大瀬55-1 20211009
7 37 相模洋(株) 神奈川県小田原市千代829 20211019
8 38 臼井商店 神奈川県海老名市本郷4240 20211019
(LearningPython) MacBookPro:HelloExcel $
一番左にindexとして0〜8が割り振られていて、全てのデータがそのままプリントされているような状況です。これを登録番号のカラムをindexに使うことも可能ですが、そのあたりのPandasの使いこなし方については、また別途纏めたいと思います。
ともかく、このステップでは無事にExcelファイルのデータがPythonプログラムで読み込めるということを確認してください。
またDataFrameはその機能はとてもパワフルですが、データ自体が特別な形で格納されている訳ではないこともお分かりいただけたと思います。
ステップ2
#!/usr/bin/env python3.8
import pandas as pd
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
for index, row in df.iterrows():
print(row[2])
解説
# print(df) for index, row in df.iterrows():
先ほどDataFrame全量を取得していたコードはコメントアウトします。
その上で、DataFrameを1行1行繰り返し処理するfor文を書きます。for-inについては制御構文を参照してください。
DataFrameにはiterrowsという行をイテレータとして処理するためのメソッドが用意されています。
print(row[2])
ご想像の通り、3カラム目を出力するにはrow[2]にアクセスします。とても素直なアプローチで住所が記載されている欄に繰り返し処理が加えられることになりました。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample02.py 神奈川県小田原市栢山2322 神奈川県川崎市麻生区向原2-11-8 神奈川県茅ヶ崎市赤羽根2260 神奈川県相模原市南区新磯野2-22-11 神奈川県海老名市門沢橋5-10-33 神奈川県相模原市緑区鳥屋530-2 埼玉県八潮市大字大瀬55-1 神奈川県小田原市千代829 神奈川県海老名市本郷4240 (LearningPython) MacBookPro:HelloExcel $
上手くいきましたでしょうか。上手くいったならば住所の欄のみが出力されたはずです。
DataFrameにはもっと直接的に3カラム目だけを対象に処理することも可能です。そのあたりはぜひPandasを研究してみてください。
ステップ3
#!/usr/bin/env python3.8
import pandas as pd
import re
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
for index, row in df.iterrows():
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
if b:
address = row[2][:b.start()]
print(address)
else:
print("not matched!")
pass
解説
import re
まずは正規表現をつかって文字列操作をしたかったので、reをimportしています。
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
続いて住所欄を表示していたprint文はコメントアウトしています。
その上で、正規表現で半角と全角の数値を検索しています。正規表現についてはこちらでは説明しませんが、例えば[1-3]と書けば1か2か3ということになります。 | は「または」を表していています。つまり[0-9]|[0-9]は、0|1|2|3|4|5|6|7|8|9|0|1|2|3|4|5|6|7|8|9と同じです。とにかく数字を捕捉したいのでこのようにしています。
if b:
address = row[2][:b.start()]
print(address)
search()はマッチしなかった場合にNoneを返すので、このようにif文を書いてマッチした場合の処理を記載しています。
start()は、マッチした先頭のindexを返します。row[2]には「xx県yy市zz町1−2−3」にようになっていますので、[:b.start()]とすると1−2−3部分が切り取られた文字列であるxx県yy市zz町が返されます。
何をやっているかというと、この後郵便番号を調べるときに1−2−3の部分は余分なだけでなく結果が0件という悲しい状態となりますので、この処理を必要としています。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample03.py 神奈川県小田原市栢山 神奈川県川崎市麻生区向原 神奈川県茅ヶ崎市赤羽根 神奈川県相模原市南区新磯野 神奈川県海老名市門沢橋 神奈川県相模原市緑区鳥屋 埼玉県八潮市大字大瀬 神奈川県小田原市千代 神奈川県海老名市本郷 (LearningPython) MacBookPro:HelloExcel $
無事に数字より後の文字列が取り除かれましたでしょうか。
ステップ4
#!/usr/bin/env python3.8
import pandas as pd
import re
import requests
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
for index, row in df.iterrows():
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
if b:
address = row[2][:b.start()]
# print(address)
r = requests.get("https://postcode.goo.ne.jp/search/q/" + address + "/?type=address")
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
print(r.text)
break
else:
print("not matched!")
解説
import requests
HTTPsリクエストを送信するためにrequestsをimportしています。
# print(address)
r = requests.get("https://postcode.goo.ne.jp/search/q/" + address + "/?type=address")
前のステップで住所を表示していたprint文はコメントアウトしています。
そしてrequestsをつかってGETリクエストを送信しています。郵便番号を検索するためにこのプログラムでは以下のサイトを利用しています。特にこういった行為を禁止しているという文面も見当たりませんし、常識の範囲内であればプログラムからのアクセスも許容されると判断してのことですが、もし何らかご迷惑をお掛けしているようであれば、お気づきの点ご教示ください。(その場合当サイトもgooのクローラーはお断りと、どこか隅っこにでも文章で書いておきます)
少し脱線しました。このあとrequestsを少しだけ見てみましょう。
print(r.status_code)
print(r.headers['content-type'])
print(r.encoding)
print(r.text)
break
まずHTTPのレスポンスのステータスコード、そしてHTTPヘッダで返ってきたContent-type、それから中身を読むときのエンコーディング、最後にBodyそのものをそれぞれprintしています。
最後にbreakしているのは、この段階ではExcelの行の数分だけ、間髪入れず連続リクエストしてしまうためです。実際には一定の間隔をあけて「常識の範囲内」でのリクエストになるようにします。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample04.py 200 text/html; charset=UTF-8 UTF-8神奈川県小田原市栢山の郵便番号 - goo郵便番号 ・ ・ ・ (LearningPython) MacBookPro:HelloExcel $
とても長いので途中を省略して掲載しましたが、想定通りでしょうか。この結果の中から郵便番号を手に入れる必要があります。
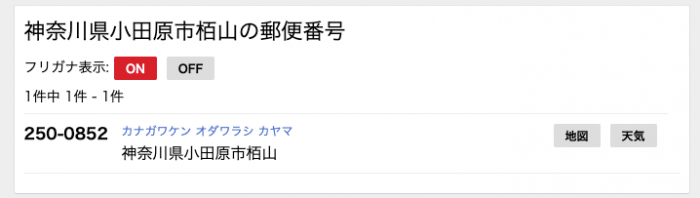
<dl class="result mb10 cx"><dt>250-0852</dt>
核心部分だけを抜粋しました。「神奈川県小田原市栢山」の郵便番号は250-0852のようです。実際にブラウザでアクセスしてみると以下のような結果になります。
ステップ5
#!/usr/bin/env python3.8
import pandas as pd
import re
import requests
from html.parser import HTMLParser
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
class Parser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.parent = False
self.result = False
self.data = []
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
if tag == "dl" and "class" in attrs and attrs['class'] == "result mb10 cx":
self.parent = True
if self.parent is True and tag == "dl":
self.result = True
def handle_data(self, data):
if self.parent is True and self.result is True:
m = re.search("-", data)
if m and m.start() == 3:
self.data.append(data)
self.title = False
self.link = False
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
for index, row in df.iterrows():
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
if b:
address = row[2][:b.start()]
# print(address)
r = requests.get("https://postcode.goo.ne.jp/search/q/" + address + "/?type=address")
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
# print(r.text)
parser = Parser()
parser.feed(r.text)
parser.close()
for data in parser.data:
print(data, end=",")
break
else:
print("not matched!")
解説
from html.parser import HTMLParser
これは先ほどのステップで得られたHTMLを処理して郵便番号部分を取り出すために、まずはHTMLParserをimportしています。
狙っているのは以下の郵便番号部分。”result mb10 cx”をクラスの値に持つdlタグの子としてdtタグを探し郵便番号を取得したいというものです。
<dl class="result mb10 cx"><dt>250-0852</dt>
class Parser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.parent = False
self.result = False
self.data = []
HTMLParserを継承したParserクラスを定義します。
コンストラクタでは、親タグを見つけたかどうか、結果を表示しているタグを見つけたかどうかのTrue/Falseを格納する変数と、実際に抽出した郵便番号を格納するためのリストを準備しています。何故リストにしているかというと、検索の方式と地名の特性として「銀座」で検索し「銀座」と「銀座西」が存在すると2件結果が返ってくるといったことがあるためです。
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
if tag == "dl" and "class" in attrs and attrs['class'] == "result mb10 cx":
self.parent = True
if self.parent is True and tag == "dt":
self.result = True
HTMLを読み込んで行き、タグを発見するたびに反応するのがhandle_starttag()です。引数はtagとattrsでそれぞれタグと属性(アトリビュート)が格納されていて、attrsはdict()を経由して辞書にしています。
これでタグがdlで、クラスが”result mb10 cx”であった場合、parentフラグを立てます。
同様に、parentフラグが立っていて、タグがdtであればresultフラグを立てています。
def handle_data(self, data):
if self.parent is True and self.result is True:
m = re.search("-", data)
if m and m.start() == 3:
self.data.append(data)
self.title = False
self.link = False
タグに囲われたデータに反応するのがhandle_data()です。先に二つのフラグを立ててあるのでそれを見て郵便番号のデータであるかどうかを判断しています。
郵便番号かどうかの判定にはもう一手間加えていて、4桁目が「-」かどうかもチェックして、結果格納用のリストに入れています。
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
# print(r.text)
parser = Parser()
parser.feed(r.text)
parser.close()
for data in parser.data:
print(data, end=",")
requestsのレスポンス関連の情報はコメントアウトします。
parserクラスを使って、レスポンスのBodyであるr.textを引き渡して処理させます。
parser.dataにリストで結果が入っているはずなので、それをforループで取り出し、表示しています。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample05.py 250-0852 (LearningPython) MacBookPro:HelloExcel $
無事に郵便番号を抽出できましたでしょうか。
ここではタグとクラスでそしてその次に出てきたタグで目指すデータであると認定し、最後にデータの形式として”-“が4桁目に入っていることをチェックしています。もっとするなら”^\d{3}-\d{4}$”とすることで3桁の数字とハイフンと4桁の数字という風にやっても良いかもしれません。その場合にはstart()不要になっていますね。
ステップ6
#!/usr/bin/env python3.8
import re
import time
from html.parser import HTMLParser
import pandas as pd
import requests
FILE_NAME = "sample.xlsx"
SHEET_NAME = "番号順"
class Parser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.parent = False
self.result = False
self.data = []
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
if tag == "dl" and "class" in attrs and attrs['class'] == "result mb10 cx":
self.parent = True
if self.parent is True and tag == "dt":
self.result = True
def handle_data(self, data):
if self.parent is True and self.result is True:
m = re.search("^\d{3}-\d{4}$", data)
# if m and m.start() == 3:
if m:
self.data.append(data)
self.title = False
self.link = False
df = pd.read_excel(FILE_NAME, sheet_name=SHEET_NAME, header=0)
# print(df)
df['郵便番号'] = ""
for index, row in df.iterrows():
# print(row[2])
b = re.search('[0-9]|[0-9]', row[2])
if b:
address = row[2][:b.start()]
# print(address)
r = requests.get("https://postcode.goo.ne.jp/search/q/" + address + "/?type=address")
# print(r.status_code)
# print(r.headers['content-type'])
# print(r.encoding)
# print(r.text)
parser = Parser()
parser.feed(r.text)
parser.close()
if len(parser.data) == 0:
print()
for data in parser.data:
print(data)
df.at[index, '郵便番号'] = ','.join(parser.data)
else:
print("not matched!")
time.sleep(3)
df.to_excel('NEW_' + FILE_NAME, sheet_name='NEW_' + SHEET_NAME, index=False)
解説
import time
複数行を処理するときにスリープを入れたいので、timeをimportしました。
df['郵便番号'] = ""
DataFrameに郵便番号カラムを追加しています。デフォルト値として空の文字列を指定している状態です。
if len(parser.data) == 0:
print()
検索した結果としてなにもヒットしないとparser.dataが空になっているはずです。そのため画面表示で空行になるようにしています。
df.at[index, '郵便番号'] = ','.join(parser.data)
そして、DataFrameのatをつかって郵便番号を格納していっています。文字列にはjoin()が用意されていて、リストをその文字で連結する機能があります。123-0001,123-0002といった文字列を作り出してそれをカラムに収めています。
time.sleep(3)
Excel各行の処理につき3秒間の待ちを設けています。
df.to_excel('NEW_' + FILE_NAME, sheet_name='NEW_' + SHEET_NAME, index=False)
最後にExcelファイルへ出力しています。ここでは新しいファイルに出力しています。最後のindexは読み込み時にDataFrameで自動的についたindexを出力に含めないためにFalseを指定しています。
実行
(LearningPython) MacBookPro:HelloExcel $ python sample06.py sample.xlsx 250-0852 215-0007 253-0001 252-0325 243-0426 252-0155 250-0215 243-0417 (LearningPython) MacBookPro:HelloExcel $
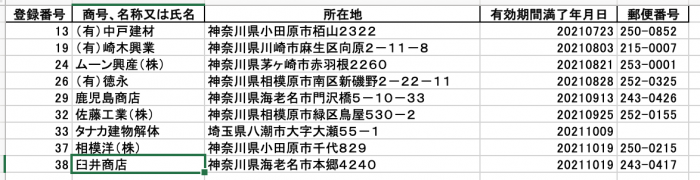
無事に取得し、Excelシートに郵便番号欄ができましたでしょうか。
1つ空欄がありますね。これは「大字」が悪さをしているようです。試しに大字を取り除くと上手く取得できます。それから今回のサンプルには2つ結果を返す住所がなかったようです。2つ返す例を探してみてトライしてみてください。複数返ってくる場合には、その1つめの値が求めている値である確率が非常に高いです。複数返ってくるのは地名の前方一致であることが多いからです。ですが、巨大なビルを要する住所の場合にはそのビルを除く値と、ビル内のフロア毎の値といった形で単純な判断が出来ません。その場合には最初に数字で切り離してしまった検索用の住所文字列のあり方そのものも考え直す必要があります。
ここではそういったケースについては取り扱いませんが「大字」に類するキーワードの特定の仕方、それから2つ以上返す場合の処理方法、もっと面倒なことをいうと京都の独特な住所など、リアルケースにはたくさんの課題があると同時に、それらを体験することがPython習得を加速させる要素であることは間違いないとおもいます。
みなさんも是非、身近なあったら良いなツールでも良いので、Pythonで解決することを模索してみてください。