Pandasでデータを取り扱うとき、ほとんどがDataframe(ソースコード上ではほとんどがdf)を使うと思いますが、そのDataFrameの基礎となる属性である行名、列名、行数、列数、要素数の取得方法について説明します。
行名と列名
DataFrameを思い浮かべるに当たってこんな感じでソースコードで示されてもイマイチイメージできないので、以下のExcelシートで考えてみます。データは左上が「高山」で右下が「男」で終わっているシートです。最上部と左端の黒い所はデータではありませんね。
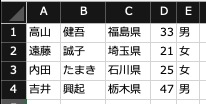
行名とは、一番左の列(姓のさらに左側)の「1,2,3,4」のことです。そうすると列名は、「A、B、C、D、E」ですね。PandasにはというかDataFrameには、データにアクセスするために行名、列名を用いたアクセス方法が用意されています。(もちろん行番号や列番号でもアクセス可能です)
df.at[行名, 列名]
サンプルデータ
高山 健吾 福島県 33 男 遠藤 誠子 埼玉県 21 女 内田 たまき 石川県 25 女 吉井 興起 栃木県 47 男
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.at[1, "姓"])
実行例
(LearningPython) MacBookPro:Pandas $ python 04.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
遠藤
(LearningPython) MacBookPro:Pandas $
解説
行名、列名でデータにアクセスするにはatを用います。具体的には df.at[1, "姓"]といった形でアクセスしますが、ここで登場するのが行名と列名です。(繰り替えにしなりますが行番号や列番号でdf.at[1, 1]といった形式でもアクセス可能です)
列名はheader変数で指定しているとおりで、今回は“姓”という文字列が用いられています。行名は特に指定していないのでintで0から順に自動的に割り振られています。意図がどうであれ、もしも以下のように行名を“1” “2” “3” …の文字列として指定したならば、もちろんdf.at["1", "姓"]となるわけです。
行名、列名を指定する方法
行名、列名を指定する方法にはいくつかあります。
index,columns属性 ・・・行名・列名をすべて変更rename()・・・任意の行名・列名を変更add_prefix()・・・列名にプレフィックス(接頭辞)add_suffix()・・・サフィックス(接尾辞)を追加
index, columns属性で指定
indexが行で、columnsが列です。ともにリストを指定することで名前を変えることが出来ます。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.at[1, "姓"])
df.index = ["1", "2", "3", "4"]
df.columns = ["Family Name", "First Name", "Hometown", "age", "gender", ]
print(df)
print(df.at["2", "Family Name"])
(LearningPython) MacBookPro:Pandas $ python 05.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
遠藤
Family Name First Name Hometown age gender
1 高山 健吾 福島県 33 男
2 遠藤 誠子 埼玉県 21 女
3 内田 たまき 石川県 25 女
4 吉井 興起 栃木県 47 男
遠藤
(LearningPython) MacBookPro:Pandas $
さて、ここではCSVファイルの読み込みからの流れなので、read_csv()が登場しています。列名については、read_csv()ではheader=None(CSVファイルにヘッダ無し)で別途names=headerとして与えていますが、変更するときはcolumnsというなんともすっきりしない感じがありますが仕方ありません。(ちゃんと統一してよって思うんですけどね、ブツブツブツ)
ここでは、新しい行名は”1″からはじめています。変わったのか変わってないのかprint(df)で区別がつかないので。列名は英語にしてみました。atでは行名、列名を指定するので、同じ「遠藤」を得るためにはdf.at["2", "Family Name"]とする必要があるというわけです。
rename()
rename()では辞書を指定することで個別に変更が可能です。df.rename(columns={'姓': 'Family Name'}, index={1: 'one'})といった具合に指定すると、その列、その行だけ名前が変わります。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.at[1, "姓"])
df = df.rename(columns={'姓': 'Family Name'}, index={1: 'one'})
print(df)
print(df.at["one", "Family Name"])
(LearningPython) MacBookPro:Pandas $ python 06.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
遠藤
Family Name 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
one 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
遠藤
(LearningPython) MacBookPro:Pandas $
ここで忘れてはいけないポイントとしては、indexは[0, “one”, 2, 3]というリストで表現可能という事実です。いまのところ1行だけ名前が文字列な点に注意しましょう。
add_prefix()とadd_suffix()
似たもの同士なので一度にご紹介します。名前から想像できるかも知れませんが、一律前に「変更前_」とか後に「_NEW」のように、現在の名前を元にして接頭辞、接尾語を付けたい場合に使用します。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.at[1, "姓"])
df = df.add_prefix('変更前_')
print(df)
(LearningPython) MacBookPro:Pandas $ python 07.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
遠藤
変更前_姓 変更前_名 変更前_出身地 変更前_年齢 変更前_性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
(LearningPython) MacBookPro:Pandas $
※add_suffix()の例は割愛します。
なお、先にご紹介したrename()ではラムダ式も使えるので、それを用いてadd_prefix/suffixの代用も可能です。
行数、列数、要素数
続いては、行数、列数、要素数です。個人的には要素数が欲しくなったことはそれほどないのですが、行数や列数は古典的というか原始的というか、もっとも直感的なアクセス方法である[1, 1]とか[2, 1]のような要素の位置でデータにアクセスしようとすると、0〜行数分だけループしたりすることがありえて、割と頻繁にお目にかかるかと思います。
ループの話は別の投稿に譲るとして、ここでは行数、列数、要素数の求め方をご紹介します。
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.shape)
print("行数: ", df.shape[0])
print("列数: ", df.shape[1])
print("要素数: ", df.size)
実行例
(LearningPython) MacBookPro:Pandas $ python 08.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
(4, 5)
行数: 4
列数: 5
要素数: 20
(LearningPython) MacBookPro:Pandas $
解説
df.shape
df.shapeが(行数, 列数)のタプルを返却します。1つ目が行、2つ目が列、「行列」の順なので覚えやすいですね。
その他の方法としては、行数はlen(df)、列数がlen(df.columns)で取得可能なのですが、表現が行と列で非対称なので、個人的にはshape一択です。
df.size
続いて要素数についてですが、個人的にはshapeのかけ算で求めてもそれほど損はしていないと思います。
まとめ
行数 df.shape[0]
列数 df.shape[1]
要素数 df.size