受領したデータが実際に使用したい形式と縦横が逆、なんてことは時折存在します。視点が逆だったり、データが発生する都度記録したとか、データベース(RDB)などでは設計時にカラム(列)が決めきれず後から増えてしまうので無理とか、理由はいくつかあると思います。
行と列の入れ替え
まずは行と列の入れ替えからです。
以下の例はあまり現実的ではありませんが、パッと見て何が起こっているかが把握しやすいので、今まで通りのサンプルデータをベースにします。左が元データで、行と列を入れ替えた右が目標とするデータです。
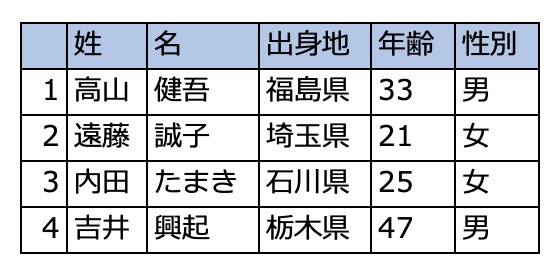
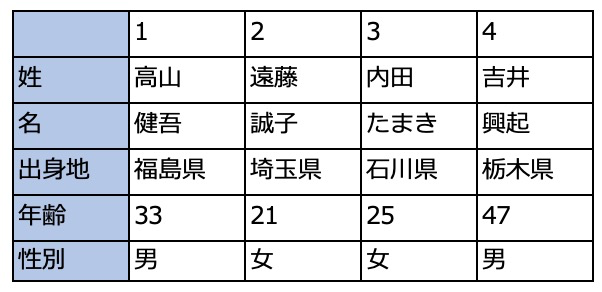
サンプルデータ
高山 健吾 福島県 33 男 遠藤 誠子 埼玉県 21 女 内田 たまき 石川県 25 女 吉井 興起 栃木県 47 男
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.T)
実行例
(LearningPython) MacBookPro:Pandas $ python 13.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
0 1 2 3
姓 高山 遠藤 内田 吉井
名 健吾 誠子 たまき 興起
出身地 福島県 埼玉県 石川県 栃木県
年齢 33 21 25 47
性別 男 女 女 男
(LearningPython) MacBookPro:Pandas $
解説
df.T
df.Tとするだけで実現可能です。同じものがdf.transpose()としても得られます。
縦持ち横持ち変換
縦持ち横持ちという言葉が広く一般的かというと自信がありませんが、心当たりのない人は幸せなことにこの機能について学ぶ必要がなく、これこれって思った人には便利な機能ということで、みんなハッピーですね。
左が縦持ちで右が横持ちと言われるデータです。キーになるものが欲しかったので今までのデータに社員番号欄を加えています。

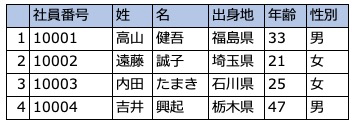
こんなデータ現実に存在しねーよって思った方は、多分ですがこの機能は不要なのだと思います。そんな人にも分かりやすく困ってみせると、社員番号を会員番号にして、項目名をアンケート項目にして、値を回答としてみてください。項目がどんどん増える場合に横持ちで対応出来ますでしょうか?
それから機械から上がってくるデータを想像してみると、デバイスIDと時刻でユニークになり、各センサーから値が報告されてくる場合はどうでしょうか。
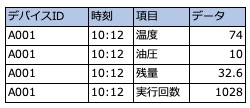
こんな感じで各デバイス毎に複数のセンサーが各値を報告してくるので、それをひたすらロギングしているシステムからデータを集め、ある時刻のデバイスAの温度、油圧、残量、実行回数の値をデータベースに格納するといったイメージです。
話を戻して実際にやってみます。
サンプルデータ
10001 姓 高山 10001 名 健吾 10001 出身地 福島県 10001 年齢 33 10001 性別 男 10002 姓 遠藤 10002 名 誠子 10002 出身地 埼玉県 10002 年齢 21 10002 性別 女 10003 姓 内田 10003 名 たまき 10003 出身地 石川県 10003 年齢 25 10003 性別 女 10004 姓 吉井 10004 名 興起 10004 出身地 栃木県 10004 年齢 47 10004 性別 男
サンプルコード
import pandas as pd
input_file_name = "sample2.csv"
header = ["社員番号", "項目名", "値"]
data_type = {"社員番号": str, "項目名": str, "値": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.pivot(index="社員番号", columns="項目名"))
実行例
(LearningPython) MacBookPro:Pandas $ python 14.read_csv.py
社員番号 項目名 値
0 10001 姓 高山
1 10001 名 健吾
2 10001 出身地 福島県
3 10001 年齢 33
4 10001 性別 男
5 10002 姓 遠藤
6 10002 名 誠子
7 10002 出身地 埼玉県
8 10002 年齢 21
9 10002 性別 女
10 10003 姓 内田
11 10003 名 たまき
12 10003 出身地 石川県
13 10003 年齢 25
14 10003 性別 女
15 10004 姓 吉井
16 10004 名 興起
17 10004 出身地 栃木県
18 10004 年齢 47
19 10004 性別 男
値
項目名 出身地 名 姓 年齢 性別
社員番号
10001 福島県 健吾 高山 33 男
10002 埼玉県 誠子 遠藤 21 女
10003 石川県 たまき 内田 25 女
10004 栃木県 興起 吉井 47 男
(LearningPython) MacBookPro:Pandas $
解説
df.pivot(index=”行にしたいカラム名”, columns=”列にしたいカラム名”)
このdf.pivot()ですが、実際にはvalue=["値"]が省略された状態にあります。省略すると残りのカラムが全てvalueに指定されたことになりますので、要らないカラムがある場合には必要なカラムだけを選んで指定する必要があります。
indexには行にしたいカラム名を指定します。columnsには列にしたいカラム名を指定します。今回は社員番号に対して、姓、名、出身地、年齢、性別を横並びにしたいので、df.pivot(index="社員番号", columns="項目名")となりました。
indexやcolumnsは、過去にはリストが指定できなかったようですが、現在ではリストの指定が可能です。
最後に大事なポイントとして、indexやcolumnsに指定する列の組み合わせが重複するとエラーになります。冷静に考えて、社員番号と姓の組み合わせで10001が山田さんで田中さんだったら無理ゲーですよね。そういうことです。