すでにちらほらと登場していますが、まずは改めて値へのアクセス、変更について取り上げます。
値へのアクセスと変更
使用するデータ
紹介するのはatとiatです。ほかにもlocやilocなどもあるのですが、個人的にお目にかかる機会が無かったので、今の時点では取り上げません。
サンプルデータ
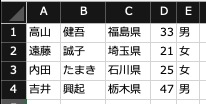
高山 健吾 福島県 33 男 遠藤 誠子 埼玉県 21 女 内田 たまき 石川県 25 女 吉井 興起 栃木県 47 男
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
print(df.at[0, "姓"])
print(df.iat[0, 0])
実行例
(LearningPython) MacBookPro:Pandas $ python 10.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
高山
高山
(LearningPython) MacBookPro:Pandas $
解説
df.at[行名, 列名]
atは行名と列名でアクセスします。列名はリストで指定しているので”姓”という文字列で、行名は指定が無いので自動で振られたintの0でアクセスしています。
df.iat[行番号, 列番号]
iatは行番号と列番号でアクセスします。従って常にintの値を指定します。すでにご紹介済みの行数と列数である行番号は0からdf.shape[0] - 1までの数であり、列番号は0からdf.shape[1] - 1までの数を指定する必要があります。
atもiatもともに値の変更も可能です。
forループ (その1)
続いて最も直接的にデータを加工しようとした場合に、何度もお世話になるforループとの関係です。
最も直感的な1-1,1-2という形でアクセスする方法を書き表してみます。
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
for i in range(df.shape[0]):
for j in range(df.shape[1]):
print(df.iat[i, j])
実行例
(LearningPython) MacBookPro:Pandas $ python 11.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
高山
健吾
福島県
33
男
遠藤
誠子
埼玉県
21
女
内田
たまき
石川県
25
女
吉井
興起
栃木県
47
男
(LearningPython) MacBookPro:Pandas $
解説
df.iat[行番号, 列番号]でデータにアクセス可能であること、df.shape[0]とdf.shape[1]を利用して行と列の数分だけループを回した形になります。
もちろん内側のループは止めて、df.at[i, "姓"]といったアクセスの仕方も考えられますね。実際には内側のループは使わない事の方が多いかも知れません。
そして大事な事ですが、このループはdfの値に直接アプローチしているため値の変更も可能です。
forループ (その2)
続いて別の方法によるループです。先ほど「大事な事」と書いたので、お察しの方もいらっしゃるかと思いますが、値の変更がある意味不可能なやり方です。
サンプルコード
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
# データの変更には使用しないこと(rowはコピーされたもの)
for i, row in df.iterrows():
if i == 1:
row["姓"] = "松本"
print(row["姓"])
print(df)
実行例
(LearningPython) MacBookPro:Pandas $ python 12.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
松本
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
(LearningPython) MacBookPro:Pandas $
解説
せっかく「松本」に変更したつもりだったし、念のため変更されていることを確認までしたのに、最後のprint(df)で見てみると変わっていません。
データにアクセスするという意味では問題ありません。ですがdf.iterrows()が返しrowに格納されるのは、dfのデータのコピーでしかありません。したがって、いくら加工しようとも元のdfには無影響なのです。
ただし、ループカウンターのiには行番号が入っているので、最後に結果を反映させる時にだけdf.iat[i, "姓"] = "松本"といった形で処理すれば問題ありません。
また行でループできるということは列でもループが出来ます。が、まぁ必要に迫られたらでも良いかなと思います。(また新たな命名が為されていて、正直に気に入りません)