データがCSV(カンマ区切り以外も可)ファイルで与えられているケースはよくあると思います。また解説のためのデータが、プログラム内でデータがセットされてもイメージしづらいかと思いますので、基本的にここで紹介したロジックをベースに他の例も示します。
CSVファイルからの読み込み
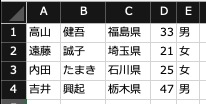
イメージし易いようにExcelシート上で展開したデータが以下です。
実際のデータは以下です。CSVと言いながら見やすさを優先して区切り文字をタブにしています。
サンプルデータ
高山 健吾 福島県 33 男 遠藤 誠子 埼玉県 21 女 内田 たまき 石川県 25 女 吉井 興起 栃木県 47 男
各カラムのヘッダは左から順に、姓、名、出身地、年齢、性別のデータになっています。
サンプルコード
CSVをPandasで読み込み、画面に出力しています。実際にはタブ区切りなので区切り文字をタブに指定し、ヘッダは外部から与えて、読み込み時の各列の型の指定をしています。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別",]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
print(df)
実行例
(LearningPython) MacBookPro:Pandas $ python 01.read_csv.py
姓 名 出身地 年齢 性別
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
(LearningPython) MacBookPro:Pandas $
解説
pd.read_csv()
このサンプルにおいては、pd.read_csv()がことの全てですね。
第1引数: input_file_name
まず1つ目の引数はファイル名です。これだけでもCSVファイルを指定さえすれば動作します。
第2引数: sep=”\t”
今回はカンマ区切りではなくタブ区切りにしているので、sepでタブを指定しています。指定を省略するとカンマになっています。なお覚える理由もありませんが、TSV(タブ区切り)ファイル向けにread_table()という関数も用意されています。
第3引数: header=None
header=Noneを指定しないと、ファイルの1行目が代わりにカラム名として使用されます。今回はいきなりデータが始まっているので指定しています。
データの1行目をカラム名として用いたい場合には、header=0と指定しますが、これがデフォルト値なので指定しなくても同じ動作になります。header=1とした場合には2行目が用いられ、1行目は無視されます。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
# df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
df = pd.read_csv(input_file_name, sep='\t', header=1)
print(df)
(LearningPython) MacBookPro:Pandas $ python 03.read_csv.py 遠藤 誠子 埼玉県 21 女 0 内田 たまき 石川県 25 女 1 吉井 興起 栃木県 47 男 (LearningPython) MacBookPro:Pandas $
第4引数: names=header
カラム名がファイル内で提供されないのでListで指定しています。指定しなかった場合には、数値が0から順にあてがわれます。これは行名が0から順にあてがわれているのと同じです。
import pandas as pd
input_file_name = "sample.csv"
header = ["姓", "名", "出身地", "年齢", "性別", ]
data_type = {"姓": str, "名": str, "出身地": str, "年齢": int, "性別": str}
# df = pd.read_csv(input_file_name, sep='\t', header=None, names=header, dtype=data_type)
df = pd.read_csv(input_file_name, sep='\t', header=None)
print(df)
(LearningPython) MacBookPro:Pandas $ python 02.read_csv.py
0 1 2 3 4
0 高山 健吾 福島県 33 男
1 遠藤 誠子 埼玉県 21 女
2 内田 たまき 石川県 25 女
3 吉井 興起 栃木県 47 男
(LearningPython) MacBookPro:Pandas $
第5引数: dtype=data_type
最後にカラムのデータ型の指定です。何の指定もしなくても、勝手に判定して読み込ませることは可能です。ですが、電話番号を読み込ませると頭の”0″が欠落するといった、Excelでもありがちな問題に遭遇します。基本的には型を指定することをおすすめします。
指定するのは辞書で、キーは第4引数で指定したカラム名です。全てを指定する必要は無く、電話番号のカラムだけstrにし残りは自動判定指せるべく{"tel": str}のみといった指定も可能です。
返値
返却されるのはDataFrameという形式のデータです。
print(df)
続いてprint文です。ここではDataFrame自体を引数にしています。
自動的に文字列にして表示されますが、列や行の数が多くなると適当に省略された状態で表示されます。
備考
行名、列名については、別途解説します。